k8s入门 前置知识 1.私有网络VPC
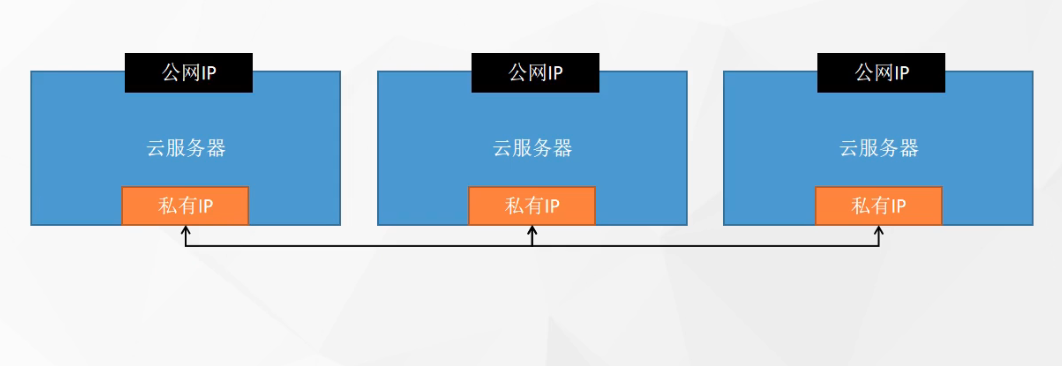
在集群内通过设置VPC来进行私有网络(专有网络)配置。
集群内的机器通过私有IP进行访问,这样不需要走公网IP的流量,访问时也不会因为公网的带宽限制。一般云服务器都会默认分配对应的专有网络,也可以自己配置专有网络。
若自己配置专有网络,需要配置IP网段,这个网段标志着这个专有网络最多能容纳多少台服务器。
比如配置的网段是:192.168.0.1/16(192.168.0.0 ~ 192.168.255.255)其中头尾IP被占用,剩下的IP就可以分配给对应的服务器,之后就可以通过私有网络进行访问。
在一些云产商,在配置了专用VPC之后,还可以配置交换机。再一级的细分网段。
所以比如这时可以加两个交换机(192.168.0.1/24)(192.168.10.1/24)。
如果创建了多个VPC,VPC与VPC之间是相互隔离的,相互VPC之下的机器是无法互通。
基本概念
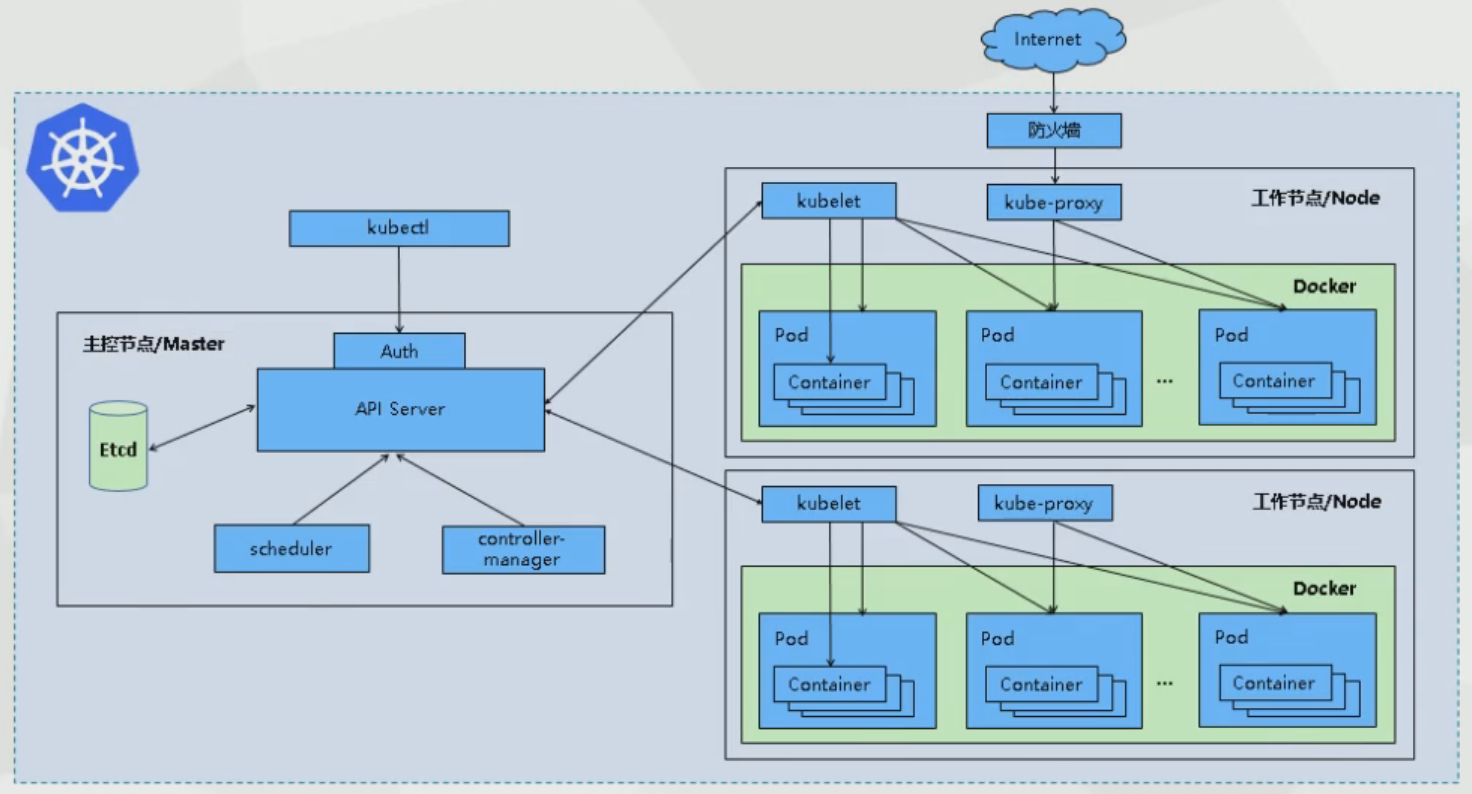
Pod:是K8s调度的基本单位,一个Pod中支持多个容器,其中多个容器共享网络和文件系统,可以通过进程通信和文件共享这种简单高效的方式组合完成服务。每个Pod都有一个特殊的根容器Pause容器,以及一个或多个的业务容器组成。Pause容器作为根容器,以它的状态来代表这个Pod的运行状态,每个Pod都分配了一个唯一的IP地址(Pod IP)。Pod内的所有业务容器都共享根容器的Ip,以及共享根容器挂载的Volume。
Node:是Pod真正运行的主机,可以是物理机也可以是虚拟机,为了更好的管理Pod,在每个Node节点上至少要容器引擎(docker)、kubelet、kubelet-proxy服务。
Namespace:命名空间,是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或者用户组。
Label:是k8s对象的标签,以键值的方式附加到各种资源上,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源上,k8s通过Label Selector(标签选择器)来查询和筛选某些Label资源对象。
Service:是一个服务的访问入口,通过标签选择器Label Selector与Pod副本集群之间进行对接,定义了一组的Pod访问策略(iptable),防止Pod失联。在创建Service时会自动为它分配一个虚拟的IP地址,即Cluster IP,服务发现就是通过Service的Name和ClusterIP地址做了一个DNS域名映射来解决。
RepllcaSet(RC):用来确保预期的Pod副本数量,如果有过多的Pod副本运行,则会停止一些,反之则再启动一些。一般很少主动操作RC,都是通过Deployment这个更高层次的资源对象使用,从而形成一整套Pod创建、删除、更新的编排机制。
Deployment:用于部署无状态应用,只需要在Deployment上描述想要的目标状态,它就会将Pod和RC的实际状态改变到目标状态。
架构组件
k8s主要由以下核心组件组成: 在k8s集群中分为master主节点和node工作节点。
在主节点中:(控制平面)
kube-apiserver:提供了资源操作的唯一入口,各组件的协调者,以Http Rest方式提供接口服务,所有对象资源的增、删、改、查和监听都交给它处理后再提交到etcd中存储。
etcd:键值数据库,保存了整个集群的一些信息。比如Pod、Service等对象信息。
kube-scheduler:调度器,根据调度算法为新创建的Pod选择一个node工作节点,可以任意部署,可以部署在同一个工作节点上,也可以部署在不同的工作节点上。
kube-controller-manager:是所有资源对象的自动化控制中心,一个资源对应一个控制器,而它就是负责管理这些控制器。比如有:
节点控制器
任务控制器
端点控制器
副本控制器
服务账户与令牌控制器
在工作节点中:
kubelet:它是master主节点在node工作节点上的agent(代理),主节点通过它来管理当前工作节点的运行容器的生命周期,负责Pod对应容器的创建、启停等,实现集群管理的基本功能。
kube-proxy:在工作节点上实现Pod网络代理,实现kubernets Service的通信,维护网络规则和四层负责均衡工作。
docker engine:容器引擎,负责本机的容器创建和管理工作。
部署k8s 环境部署前遇到的一些问题
由于需要使用到yum来下载一些包,但是yum需要访问镜像仓库,始终无法访问到 mirrorlist.centos.org,所以需要更换为国内的的一些镜像源。
1 2 3 4 5 6 7 8 9 10 cd /etc/yum.repos.d/wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.163.com/.help /CentOS7-Base-163.repo
添加安装docker镜像源,这个命令执行之后,会在/etc/yum.repos.d目录下生成docker-ce.repo文件。是专门针对docker的软件包镜像源。
1 2 3 sudo yum-config-manager \ --add-repo \ https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker,安装docker要注意需要和k8s版本匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 yum -y install docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io systemctl start docker docker version sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors" : ["https://gr4yxx0x.mirror.aliyuncs.com" ], "exec-opts" : ["native.cgroupdriver=systemd" ], "log-driver" : "json-file" , "log-opts" : { "max-size" : "100m" }, "storage-driver" : "overlay2" } EOF sudo systemctl daemon-reload sudo systemctl restart docker docker info
接着就可以开始安装K8S
设置hostname,每台服务器的主机名不可重复。
1 2 3 4 5 6 7 8 9 hostname hostnamectl set-hostname k8s-master hostnamectl set-hostname k8s-node-1 bash
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 free -m setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl --system
安装k8s三大件(kubelet、kubeadm、kubectl)版本使用1.20.9
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes systemctl enable --now kubelet systemctl status kubelet
在k8s组件中,除了kubelet,其他组件都是通过容器的方式下载运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 sudo tee ./images.sh <<-'EOF' #!/bin/bash images=( kube-apiserver:v1.20.9 kube-proxy:v1.20.9 kube-controller-manager:v1.20.9 kube-scheduler:v1.20.9 coredns:1.7.0 etcd:3.4.13-0 pause:3.2 ) for imageName in ${images[@]} ; do docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName done EOF chmod +x ./images.sh && ./images.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 echo "10.211.55.15 cluster-endpoint" >> /etc/hostskubeadm init \ --apiserver-advertise-address=10.211.55.15 \ --control-plane-endpoint=cluster-endpoint \ --image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16
如果使用的是云服务器要注意,至少要允许在2c的服务器上。
安装成功后会得到以下提示信息,需要根据以下信息进行操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME /.kube sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config sudo chown $(id -u):$(id -g) $HOME /.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join cluster-endpoint:6443 --token xh1xft.8m76emhyhdjr7i0o \ --discovery-token-ca-cert-hash sha256:4985192332d76a8ebead16baed30db9c43d1efdd8c26d328691005da8649d31c \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join cluster-endpoint:6443 --token xh1xft.8m76emhyhdjr7i0o \ --discovery-token-ca-cert-hash sha256:4985192332d76a8ebead16baed30db9c43d1efdd8c26d328691005da8649d31c
这时通过kubectl get nodes可以看到当前的节点状态,但是此时的主节点状态还是NotReady,是因为还需要下载一个网络组件。
1 2 3 4 5 6 7 curl https://docs.projectcalico.org/manifests/calico.yaml -O curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O kubectl apply -f calico.yaml
这里有一个问题:我使用的是阿里云的镜像加速器,但是好像一直无法下载calico镜像。所以只能通过一些非常规手段下载。创建calico.sh,之后chmod +x calico.sh && ./calico.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 tar -zxvf release-v3.20.6.tgz cd release-v3.20.6cd imagessudo tee load-images.sh <<-'EOF' #!/bin/bash tars=( calico-kube-controllers.tar calico-node.tar calico-typha.tar calico-cni.tar calico-pod2daemon-flexvol.tar ) for tar in ${tars[@]} ; do docker load < $tar done EOF chmod +x load-images.sh && ./load-images.sh
同时需要修改下载的calico.yaml中的镜像地址。(注意:如果是通过这种方式,则工作节点也需要同样操作,因为工作节点也需要这个镜像。 )
1 2 3 sed -i 's/image: docker.io\//image: /g' calico.yaml
1 2 3 4 kubeadm join cluster-endpoint:6443 --token xh1xft.8m76emhyhdjr7i0o \ --discovery-token-ca-cert-hash sha256:4985192332d76a8ebead16baed30db9c43d1efdd8c26d328691005da8649d31c
加入集群的令牌的有效期是24小时,重新获取令牌。
1 2 kubeadm token create --print-join-command
在k8s中一般都是通过.yaml来进行一些操作。
1 2 kubectl apply -f xxx.yaml kubectl delete -f xxx.yaml
我在测试时候使用的是云服务器,后面转到虚拟机上,部署了同样的环境。(不行,这个修改方式有问题,虽然乍一看修改之后是没有什么问题,通过kubectl get nodes查看的状态也是对的,但是我在创建pod的时候一直创建不起来,甚至连pod都没有去创建,也不知道是因为什么,通过systemctl status kubelet查看日志,其中有打印出还是通过旧的地址访问serverapi接口,说明哪里改漏了,没有改到,但是具体哪里就不知道了。)
1 2 3 4 5 6 7 8 systemctl start docker systemctl enable --now kubelet cd /etc/kubernetes/manifestsvi etcd.yaml vi kube-apiserver.yaml
常用命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 kubectl get nodex kubectl get ns kubectl get pods -A对应 docker 中 的docker ps kubectl get pods kubectl get pod -A -owide kubectl get pod -w
namespace 1 2 3 4 5 6 7 8 kubectl get pod -n kubernetes-dashboard kubectl create ns hello kubectl delete ns hello
pod 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 kubectl run mynginx-k8s --image=nginx kubectl exec -it Pod名字 -- /bin/bash kubectl describe pod mynginx-k8s kubectl delete pod mynginx-k8s kubectl delete pod mynginx-k8s -n xxx kubectl logs mynginx-k8s kubectl logs -f -n xxx命名空间 xxxPodName
deployment 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 kubectl create deployment mytomcat --image=tomcat:8.5.68 kubectl get deploy kubectl delete deploy mytomcat kubectl create deployment my-dep --image=nginx --replicas=3 kubectl scale deploy/my-dep --relicas=5 kubectl scale deploy/my-dep --relicas=2 kubectl get deploy/my-dep -oyaml kubectl get deploy/my-dep -oyaml | grep image kubectl set image deployment/my-dep nginx=nginx:1.16.1 --recordkubectl rollout status deployment/my-dep kubectl rollout history deployment/my-dep kubectl rollout histroy deployment/my-dep --revision=2 kubectl rollout undo deployment/my-dep kubectl rollout undo deployment/my-dep --to-revision=2
在deployment中还有一些细分:
Deployment:无状态应用部署,比如微服务,提供多副本等功能。
StatefulSet:有状态应用部署,比如redis,提供稳定的存储、网络等功能
DeamonSet:守护型应用部署,比如日志收集组件,在每个机器都运行一份。
Job/CronJob:定时任务部署,比如垃圾清理组件,可以在指定时间运行。
Service Pod的服务发现与负责均衡,将一组Pods公开为网络服务的抽象方法。如果访问是通过直接IP的方式,当其中的一个Pod或者是服务器宕了之后,就直接无法访问了,所以在k8s中,Pod的网络控制由Service管理,请求访问到Service上,由Service转到对应的Pod上,当然它也有负载均衡的能力。
Service有两种创建方式,或者说有两种创建类型
ClusterIP:默认的访问方式(创建的时候不写就是使用这种方式),只能集群内访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 kubectl expose deploy my-dep-02 --port=8000 --target-port=80 kubectl get service kubectl get pod --show-labels kubectl delete svc my-dep-02
NodePort:在公网上可以访问,但是这种方式暴露的端口是随机的。这种模式可以访问每一台服务器的暴露端口,比如创建之后生成的端口是30999,那么每一台服务器的IP:30999,都能访问到,且具备负责均衡。
1 2 3 4 5 6 7 8 kubectl expose deploy my-dep-02 --port=8000 --target-port=80 --type =ClusterIP kubectl expose deploy my-dep-02 --port=8000 --target-port=80 --type =NodePort kubectl get svc
小Tip: 使用ClusterIP类型分配的IP地址,在初始化时其实配置了IP地址的范围。下方的--service-cidr。同样的下方的--pod-network-cidr是所有的pod的IP范围。
1 2 3 4 5 6 7 kubeadm init \ --apiserver-advertise-address=172.31.0.2 \ --control-plane-endpoint=cluster-endpoint \ --image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16
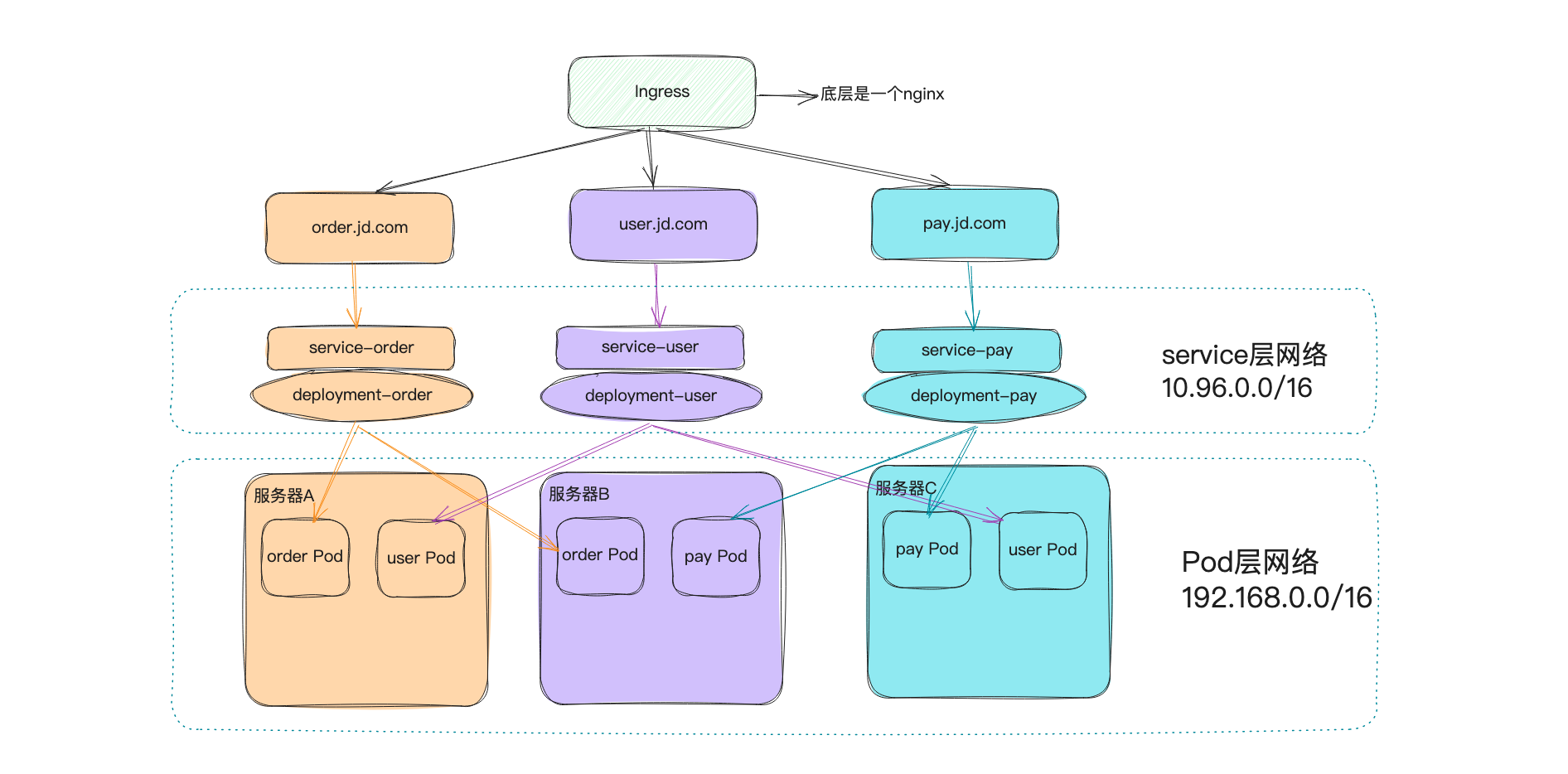
Ingress 它是Service的统一网关入口,底层是nginx。所有的请求都是先到ingress,由ingress来打理这些请求,类似微服务中的网关层。
安装ingress
1 2 3 4 5 6 7 8 9 10 11 12 13 14 wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml vi deploy.yaml registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0 kubectl apply -f deploy.yaml kubectl get pod,svc -n ingress-nginx
删除ingress
1 2 3 4 5 6 7 8 9 10 kubectl delete -f deploy.yaml kubectl get ns ingress-nginx -o json > tmp.json kubectl proxy curl -k -H "Content-Type: application/json" -X PUT --data-binary @tmp.json http://127.0.0.1:8001/api/v1/namespaces/ingress-nginx/finalize
安装之后查看安装结果,可以看到ingress-nginx-controller通过NodePort方式暴露了两个端。
31276这个是http的访问端口,31267这个是https的访问端口。
1 2 3 4 5 [root@master home] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller NodePort 10.96.2.61 <none> 80:31276/TCP,443:31267/TCP 2m44s ingress-nginx-controller-admission ClusterIP 10.96.31.252 <none> 443/TCP 2m44s
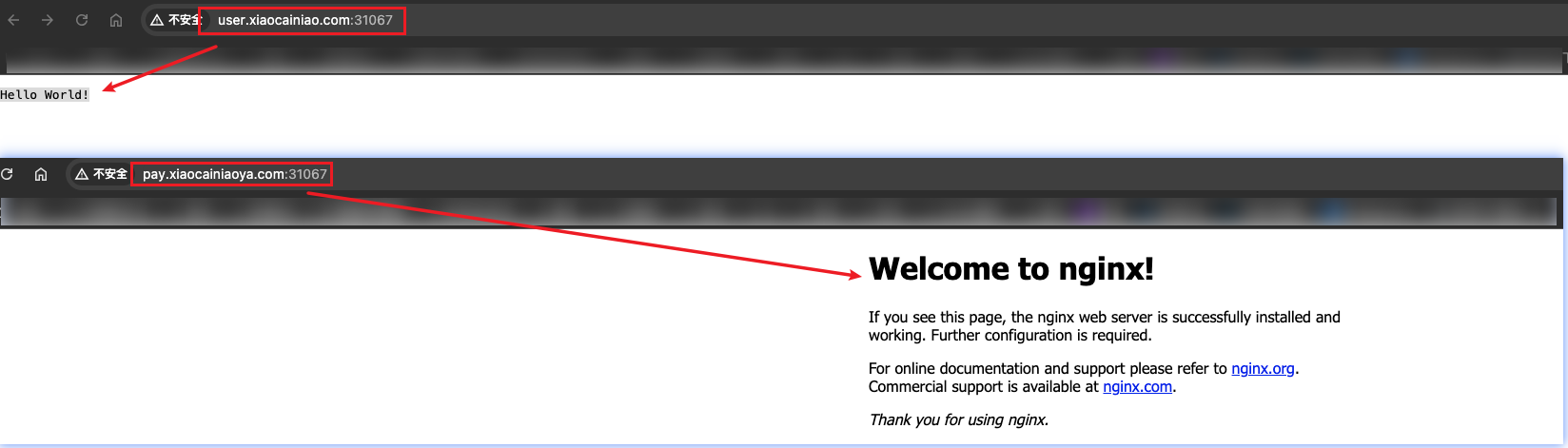
访问http://10.211.55.15:31067/出现了nginx的404页面。
这里就简单的做个ingress的测试:如果访问的是user.xiaocainiao.com那么显示”Hello World!“。如果访问的是pay.xiaocainiaoya.com那么显示的是nginx的欢迎页面。
创建两个Deployment和两个Service。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 apiVersion: apps/v1 kind: Deployment metadata: name: hello-server spec: replicas: 1 selector: matchLabels: app: hello-server template: metadata: labels: app: hello-server spec: containers: - name: hello-server image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server ports: - containerPort: 9000 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-demo name: nginx-demo spec: replicas: 1 selector: matchLabels: app: nginx-demo template: metadata: labels: app: nginx-demo spec: containers: - image: nginx name: nginx --- apiVersion: v1 kind: Service metadata: labels: app: nginx-demo name: nginx-demo spec: selector: app: nginx-demo ports: - port: 8000 protocol: TCP targetPort: 80 --- apiVersion: v1 kind: Service metadata: labels: app: hello-server name: hello-server spec: selector: app: hello-server ports: - port: 8000 protocol: TCP targetPort: 9000
然后在k8s中执行:
1 2 3 vi test.yaml kubectl apply -f test.yaml
接着创建路由规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-host-bar spec: ingressClassName: nginx rules: - host: "user.xiaocainiao.com" http: paths: - pathType: Prefix path: "/" backend: service: name: hello-server port: number: 8000 - host: "pay.xiaocainiaoya.com" http: paths: - pathType: Prefix path: "/" backend: service: name: nginx-demo port: number: 8000
然后在k8s中执行:
1 2 3 vi ingress-rule.yaml kubectl apply -f ingress-rule.yaml
刚执行完命令,可能在ADDRESS一栏为空,稍微等一等之后会分配这个ingress的访问地址。
1 2 3 4 [root@master home] NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE default ingress-host-bar nginx user.xiaocainiao.com,pay.xiaocainiaoya.com 10.211.55.16 80 12m
我是用虚拟机做测试,需要进行本机的路由代理。
1 2 10.211.55.16 user.xiaocainiao.com 10.211.55.16 pay.xiaocainiaoya.com
用这个访问地址+刚刚安装的ingress-manager暴露的端口进行访问。
存储挂载 在k8s的场景中,pod在集群中部署的节点机是由deployment决定,假设说某一个pod挂了之后,可能deployment在识别到之后通过故障恢复,会将在其他机器上重新部署一个该pod。所以这时会存在一种情况,重新部署的pod理应能读取到之前pod故障之前写入到磁盘的一些持久性数据,所以在k8s体系中,引入了存储层框架。
在k8s中可以使用的一些存储层框架:Glusterfs、NFS、CephFS。
这里以NFS为例,需要在每一台节点机上安装NFS。每个机器上安装一个NFS存储层框架,然后相互之间进行数据同步,假设某一个pod故障之后,被转移到了其他的机器上,也能通过相同的挂载目录读取到之前持久化数据。
1 2 3 4 5 6 7 8 9 10 11 12 yum install -y nfs-utils echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exportsmkdir -p /nfs/data systemctl enable rpcbind --now systemctl enable nfs-server --now exportfs -r
到此就表示,在master机器上开放了/nfs/data/目录,用来做成存储空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 showmount -e 192.168.27.251 mkdir -p /nfs/data mount -t nfs 192.168.27.251:/nfs/data /nfs/data echo "hello nfs server" > /nfs/data/test.txtcd /nfs/datals
原生方式 数据挂载
在 /nfs/data/nginx-pv 挂载,然后 修改, 里面 两个 Pod 也会 同步修改。
问题:①如果某个Pod不需要了,删掉Pod之后,文件还在,内容也在,②空间受机器空间管理,创建之后逻辑上是无限大的空间,除非达到机器上限,是没法管理大小的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-pv-demo name: nginx-pv-demo spec: replicas: 2 selector: matchLabels: app: nginx-pv-demo template: metadata: labels: app: nginx-pv-demo spec: containers: - image: nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html nfs: server: 192.168 .27 .251 path: /nfs/data/nginx-pv
1 2 3 4 5 6 7 8 9 10 11 cd /nfs/datamkdir -p nginx-pv ls vi deploy.yaml kubectl apply -f deploy.yaml kubectl get pod -owide
6.3 PV 和 PVC
PV :持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC :持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格
静态供应:在主节点上的nfs/data/目录下创建三个文件夹,并且通过yaml文件对其进行配置。
01:挂载名称为pv01-10m,且持久卷池的名称为nfs,空间为10M,多节点可读写02:挂载名称为pv02-1gi,且持久卷池的名称为nfs,空间为1G,多节点可读写03:挂载名称为pv03-3gi,且持久卷池的名称为nfs,空间为3G,多节点可读写
1 2 3 4 mkdir -p /nfs/data/01 mkdir -p /nfs/data/02 mkdir -p /nfs/data/03
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 apiVersion: v1 kind: PersistentVolume metadata: name: pv01-10m spec: capacity: storage: 10M accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/01 server: 192.168 .27 .251 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv02-1gi spec: capacity: storage: 1Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/02 server: 192.168 .27 .251 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv03-3gi spec: capacity: storage: 3Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/03 server: 192.168 .27 .251
1 2 3 4 5 6 7 8 vi pv.yaml kubectl apply -f pv.yaml kubectl get persistentvolume
创建、绑定 PCV
创建一个持久卷声明:从持久卷池子名为nfs的池子中申请一个至少有200M大小的空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nginx-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 200Mi storageClassName: nfs
绑定到pod上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-deploy-pvc name: nginx-deploy-pvc spec: replicas: 2 selector: matchLabels: app: nginx-deploy-pvc template: metadata: labels: app: nginx-deploy-pvc spec: containers: - image: nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html persistentVolumeClaim: claimName: nginx-pvc
既然有静态供应那么也就会有动态供应,在静态供应商中,是创建好了一个个不同大小的PV,并把这些PV进行分组命名(池子名称),等需要使用时,通过这个分组名称(池子名称)去这个组里获取到最适合的空间大小的PV。这种方式比较麻烦的是,需要手动创建一个个PV,且空间大小上无法相对准确的预估,容易存在浪费。比如我只需要20M的空间,但是池子里的PV分别为1G,2G,3G,那么这时至少会给我1G的那个PV。
动态供应:就是可以动态的创建具体的PV,那么这种方式创建的PV的空间大小就会相对符合需要,不会造成过多的浪费。
配置集ConfigMap 在k8s中部署POD,比如redis的启用,需要依赖于一些配置(配置一些服务器地址等),这时可以将这个配置内容添加到k8s的配置集中,那么所有的pod就可以都引用到这份配置文件,并且当需要修改配置时,只需要对这个配置集进行修改,POD中指定的配置文件也会相应的同步新的配置(一小段时间之后)。
假设我有配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 # 设置Redis监听的端口,默认为6379 port 6379 # 设置Redis监听的网络接口的IP地址 # bind 127.0.0.1 # 设置Redis是否以守护进程方式运行 daemonize no # 设置Redis的日志文件路径 logfile "/var/log/redis/redis-server.log" # 设置数据库的数量,默认16个数据库(0...15),可以通过select <dbid>命令选择数据库 databases 16 # 设置密码认证 # requirepass yourpassword # 设置快照功能,即持久化 # save <seconds> <changes> # save 900 1 # save 300 10 # save 60 10000 # 设置持久化的文件 dbfilename dump.rdb dir /var/lib/redis # 设置当主服务器失效时,从服务器是否仍然可读 slave-serve-stale-data yes # 设置是否在每个命令后进行日志记录 appendonly no # 设置更新日志的文件名 appendfilename "appendonly.aof" # 设置更新日志写入策略 # appendfsync always appendfsync everysec # appendfsync no # 设置Redis最大内存容量 # maxmemory <bytes> # 设置内存淘汰策略 # maxmemory-policy volatile-lru
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vi redis.conf appendonly yes kubectl create cm redis-conf --from-file=redis.conf kubectl get cm rm -rf redis.conf kubectl get cm redis-conf -oyaml
显示这个配置集的内容如下。(它是存储在tecd中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: v1 data: redis.conf: "# 设置Redis监听的端口,默认为6379\nport 6379\n \n# 设置Redis监听的网络接口的IP地址\n# bind 127.0.0.1\n \n# 设置Redis是否以守护进程方式运行\ndaemonize no\n \n# 设置Redis的日志文件路径\nlogfile \"/var/log/redis/redis-server.log\"\n \n# 设置数据库的数量,默认16个数据库(0...15),可以通过select <dbid>命令选择数据库\ndatabases 16\n \n# 设置密码认证\n# requirepass yourpassword\n \n# 设置快照功能,即持久化\n# save <seconds> <changes>\n# save 900 1\n# save 300 10\n# save 60 10000\n \n# 设置持久化的文件\ndbfilename dump.rdb\ndir /var/lib/redis\n \n# 设置当主服务器失效时,从服务器是否仍然可读\nslave-serve-stale-data yes\n \n# 设置是否在每个命令后进行日志记录\nappendonly no\n \n# 设置更新日志的文件名\nappendfilename \"appendonly.aof\"\n \n# 设置更新日志写入策略\n# appendfsync always\nappendfsync everysec\n# appendfsync no\n \n# 设置Redis最大内存容量\n# maxmemory <bytes>\n \n# 设置内存淘汰策略\n# maxmemory-policy volatile-lru\n" kind: ConfigMap metadata: creationTimestamp: "2024-07-24T16:02:55Z" managedFields: - apiVersion: v1 fieldsType: FieldsV1 fieldsV1: f:data: .: {} f:redis.conf: {} manager: kubectl-create operation: Update time: "2024-07-24T16:02:55Z" name: redis-conf namespace: default resourceVersion: "14777" uid: a626dec1-6e28-4ed0-a5ce-0aaeafffe12f
创建pod来引用这个配置集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: v1 kind: Pod metadata: name: redis spec: containers: - name: redis image: redis command: - redis-server - "/redis-master/redis.conf" ports: - containerPort: 6379 volumeMounts: - mountPath: /data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: redis-conf items: - key: redis.conf path: redis.conf
注:配置集是具备了热更新的能力,修改了配置集中的配置值的内容,它会同步到pod中配置的制定文件上,但是如果pod中的应用想要获取到配置热更新之后的值,应用本身得拥有热更新的能力。(所以这时可能需要重启pod来读取最新的配置值)
密钥集Secret 用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod的定义或者容器镜像中来说更加安全和灵活。
1 2 3 4 5 6 7 8 9 10 11 kubectl create secret docker-registry regcred \ --docker-server=<你的镜像仓库服务器> \ --docker-username=<你的用户名> \ --docker-password=<你的密码> \ --docker-email=<你的邮箱地址> kubectl create secret docker-registry cgxin-docker-secret \ --docker-username=leifengyang \ --docker-password=Lfy123456 \ --docker-email=534096094@qq.com
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: private-cgxin-docker spec: containers: - name: private-cgxin-docker image: cgxin/cgxin_docker:1.0 imagePullSecrets: - name: cgxin-docker-secret