redis学习笔记(二)
主从复制
主从复制是将一台redis服务器设置为主服务器master,复制到其他多台从服务slave上,主服务器负责读写操作,从服务器只能读。数据的复制只能是主服务器到从服务器。当主服务器宕机时,可以让从服务器接管主服务器接管,保证系统不至于停机,否则在主服务器重启到恢复数据的这个过程中,服务一直处于停机状态。主从服务器之间通过心跳的机制检查服务器间的连接状态
主从服务之间的数据复制通过全量复制和部分复制。
全量复制
分为两步操作:①主节点接收到从节点的全量复制命令,执行
gbsave,在后台生成RDB文件,同时将此刻之后的写操作命令添加到复制缓冲区中。②将RDB文件发送给从节点,从节点先清除本身数据后加载RDB文件,然后在将主节点的复制缓冲区写命令依次执行。从而保证了从节点和主节点的数据一致。部分复制
- 复制偏移量:主从节点分别维护一个
offset偏移量,主节点每次向从节点发送多少数据,修改offset偏移量值;同理,从节点每次从主节点接收多少数据,也会修改offset偏移量值。 - 复制积压缓冲区:主节点内部维护一个长度固定的
FIFO队列作为复制积压缓冲区,默认大小是1M,在进行命令同步时,不仅会将写命令同步到从节点,同时会将写命令写入复制积压缓冲区,由于长度固定,写入比较早的命令会被挤出缓冲区,所以当主从的offset差距大于缓冲区长度时,无法进行部分复制,只能执行全量复制。 - 服务器运行
ID(runId):每个节点都有运行ID,运行ID在节点启动时自动生成,主节点会将自己的runId发送给从节点,从节点保存起来,出现从节点断线重连:①若若从节点中保存的主runId=主runId则之前同步过该主节点数据,会首先尝试部分复制。②若从节点中保存的主runId!=现主runId,则只能全量复制。
- 复制偏移量:主从节点分别维护一个
哨兵模式
在主从复制模式下,若出现主服务器宕机,则需要运维人员手动修改从服务器为主服务器,不能良好的支持高可用。哨兵模式从出现就是为了解决这个问题,所以哨兵模式其实就是高可用的主从复制模式。可以由至少一个哨兵(哨兵可以集群),监听任意多个主从服务器,当主服务器出现异常,导致宕机的时候,由哨兵投票将某个从服务器选举为主服务器,这样就可以保证主从服务之间的高可用。
启动哨兵:redis-sentinel /path/to/sentinel.conf
Subjectively Down(SDOWN):主观下线,单个哨兵做出下线的判断。Objectively Down(ODOWN):客观下线,多个哨兵实例对同一客户端做出下线判断。
客观下线只适用于主服务器,其他从服务器或者哨兵只会主观下线。哨兵在判定它们为下线前不需要进行协商,所以从服务器或者哨兵永远不会达到客观下线的条件。理论上,主观下线的作用就是当主服务器出现客观下线时,哨兵进行选举的从服务器不会从主观下线的从服务器中选举。
redis集群
集群是为了解决单机redis容量有限的问题,将数据按一定的规则分配到多台机器中,也叫数据分片,集群不需要哨兵。
使用redis分片会遇到一个问题是如果将所有数据都均匀的分布到每一台服务器上,如果仅仅只通过key的哈希值取服务器数量的模有可能出现两个问题:
大量的哈希碰撞导致大量数据存储在了某一台或者某几台服务器上。
当出现服务器增加一台或者减少一台时,需要迁移大量的数据。
解决方案
采用一致性哈希算法进行处理。
如下图设置一个从0~2^32-1头尾相连的环。将目前集群中的服务器的ip进行哈希运算后对2^23进行取模后,得到结果一定落在这个环上的某个位置。
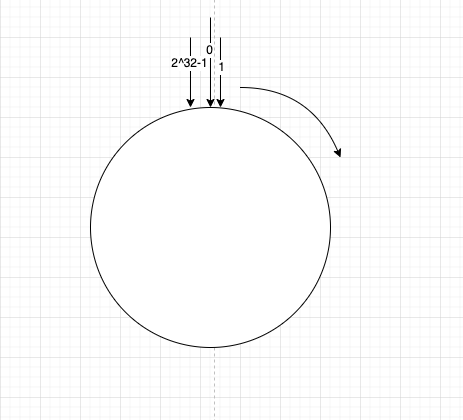
假设现在集群中有三台服务器,分别进行hash(ip)%2^23运算之后,落在环上的位置,同时对一些需要存储在服务器中的数据进行hash(key)%2^23运算之后的值也会落在这个环上。根据顺时针,将对应的键归于某台服务器上,比如下图中key1落在S1服务器上,key4落在S2服务器上,key2和key3落在S3服务器上。
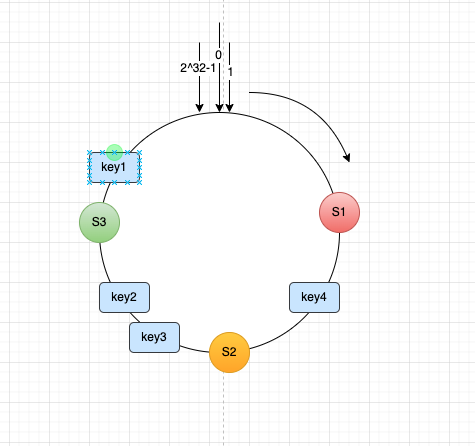
假设这时需要添加一台服务器S4,那么只需要将S4在这个环上左侧部分的数据迁移到S4服务器上,其他服务器不需要进行迁移操作,删除服务器类似,所以不论是添加或者删除服务器,仅需要集群中的两台服务器进行迁移处理。
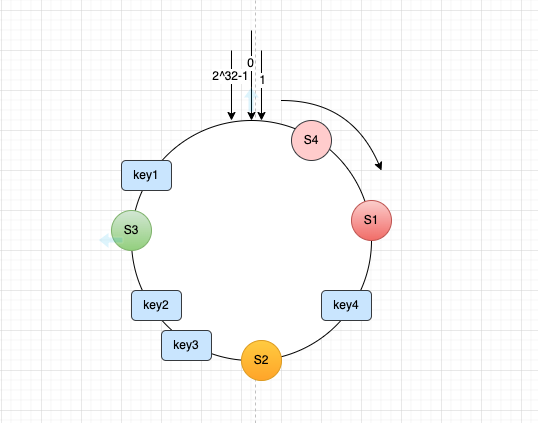
到这实际上已经解决了使用缓存集群进行分片在扩展和收缩时牵一发而动全身的数据迁移情况,但是在上面的例子中,服务的分布过于理想化,有可能出现一种场景是集群中就两台服务器,且两台服务器在这个环上距离非常靠近。业界称为数据倾斜:在存储集群中意思为大部分数据存储在少来服务器上,在计算集群中意思为大部分数据由少量服务器进行计算。
这里可以通过为服务器创建虚拟的节点,来扩大服务器在环上的分布,比如由每台服务器仅经过一次hash(ip)%2^23运算修改为ip#1、ip#2进行编号后在进行运算,使得一台服务器在环上存在多个节点,达到尽可能将数据均匀分布到各个服务器上的目的。
缓冲穿透、击穿、雪崩
缓存穿透:当某一个key对应数据在缓存中不存在同时在持久层也不存在时,如果大量的请求涌入,会造成数据库的压力,这种现象称为缓存穿透。
解决方案
- 布隆过滤器:将所有数据都打入布隆过滤器中,当通过布隆过滤器查询某个值时,若返回
false则一定不存在该数据,若返回true则可能存在数据(有一定误判率),进入redis查询,若没有命中,在进入持久层查询。 - 缓存空对象:这种做法比较粗暴,当出现数据查询不到时,将空对象缓存,一般会设置一个较短的缓存时间。
缓存击穿:当某一时刻,某一个key对应的缓存时间过期导致失效,如果大量的请求涌入,导致所有的请求都到持久层,会造成数据库压力,这种现象称为缓存击穿。
解决方案
- 使用互斥锁:使用
mutex,当缓存失效时,获取锁,在进入持久层,查询到数据后再添加到缓存中,也就是说若缓存中查询不到值,需要获取锁之后,才能进入持久层。
缓存雪崩:在某一个时刻,多个key对应的缓存时间过期,导致这些key全部失效,如果大量的请求涌入,导致所有的请求都到达持久层,会造成数据库压力,这种现象称为缓存雪崩。
解决方案
- 缓存失效随机值,尽量避免多个
key扎堆在同一时刻失效。