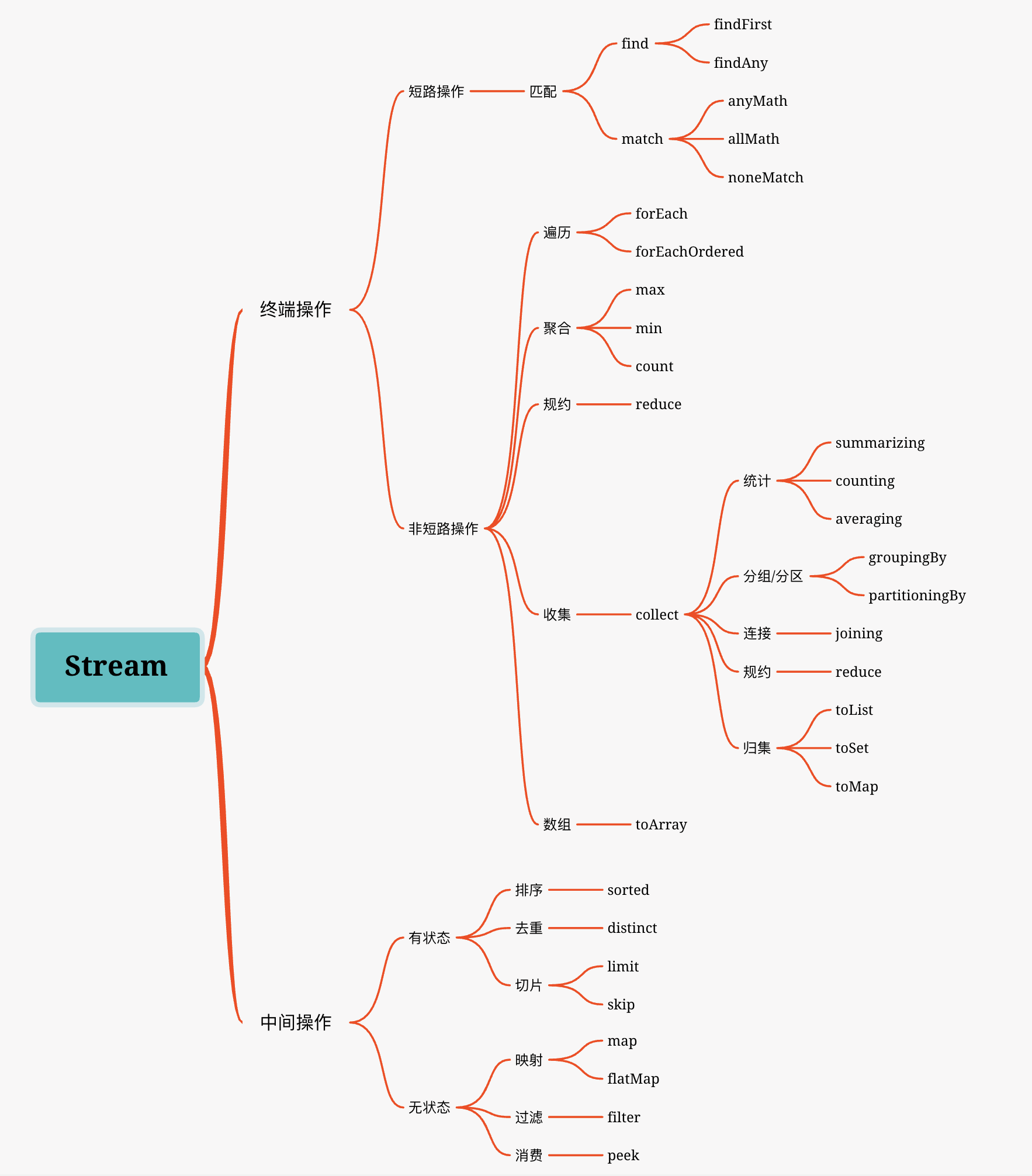
一、介绍 jdk8中引入的函数式lambda表示式,同时引入了Stream流,这种流可以堆集合进行一些复杂查找、过滤、映射、规约等操作。一个stream是由三部分组成,数据源流 ->零个或多个中间操作 -> 零个或一个终止操作。中间操作是对数据的加工处理并且中间操作是懒lazy操作,并不会马上启动,需要等待终止操作允许到才会开始执行。
Stream分为终端操作和中间操作。
终端操作:也称为结束操作,即不能在继续处理数据。
中间操作:就是可以使用上一次处理的结果进行再次处理数据。
终端操作又分为短路操作和非短路操作:
短路操作:所有数据项不一定都需要处理完成即可结束。类似于a || b,这种判断语句只要某个数据项使得a=true即结束遍历。
非短路操作:所有数据项都需要遍历一遍方才结束。
中间操作又分为有状态和无状态:
有状态:表示改操作只有等待拿到所有元素后才能继续下去。
无状态:表示元素的处理不受其他元素的影响。
比如:sorted()排序,需要获取到流中的所有元素后才能进行排序。而filter()只需要获取流中的一个元素就可以进行处理。
二、使用 2.1 终端操作 2.1.1 短路操作 2.1.1.1 匹配 1.find
通过findFirst/findAny返回的是一个Optional<T>对象。
1 2 3 4 public static void find (List<Integer> list) System.out.println(list.stream().findFirst().get()); System.out.println(list.stream().findAny().get()); }
2.match
anyMatch:数据流中仅有一个数据项满足Predicate即返回trueallMatch:数据流中所有数据项满足Predicate才返回truenoneMatch:数据流中所有数据项都不满足Predicate才返回true
注意: 当数据列表为空时, allMatch的返回值为true
1 2 3 4 5 6 7 8 9 10 public static void match (List<Integer> list) System.out.println(list.stream().anyMatch(item -> item % 2 == 0 )); System.out.println(list.stream().allMatch(item -> item % 2 == 0 )); System.out.println(list.stream().noneMatch(item -> item % 2 == 0 )); List<Integer> items = new ArrayList<>(); System.out.println(items.stream().anyMatch(item -> item % 2 == 0 )); System.out.println(items.stream().allMatch(item -> item % 2 == 0 )); System.out.println(items.stream().noneMatch(item -> item % 2 == 0 )); }
2.1.2 非短路操作 2.1.2.1 遍历
在stream.forEach中不能使用break和continue关键字, 但stream.forEach中return和 continue达到的效果一致。
在parallelStream.forEachOrdered可以使得结果有序, 但同时牺牲了并行流的好处。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void forEach (List<Integer> list) list.stream().forEach(item -> System.out.print(item)); System.out.println(); list.stream().forEach(item -> { if (item % 2 == 0 ){ System.out.print(item); return ; } }); System.out.println(); list.parallelStream().forEach(item -> System.out.print(item)); System.out.println(); list.parallelStream().forEachOrdered(item -> System.out.print(item)); System.out.println(); }
2.1.2.2 聚合
max/min/count
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static void aggregation (List<Integer> list) System.out.println(list.stream().max(Integer::compareTo).get()); Integer max = list.stream().max(new Comparator<Integer>() { @Override public int compare (Integer o1, Integer o2) return o1 - o2; } }).get(); System.out.println(max); System.out.println(list.stream().min(Integer::compareTo).get()); System.out.println(list.stream().count()); }
2.1.2.3 规约 reduce
规约: 将一个流通过一些计算/逻辑规约为一个值
第三个参数一般使用不到, 用处是在使用并行流(parallelStream)时, 最终将所有并行流的数据进行规约。
1 2 3 4 5 6 7 8 9 10 private static void reduce (List<Integer> list) System.out.println("求和: " + list.stream().reduce(0 , (a, b) -> a + b)); System.out.println("求积: " + list.stream().reduce(1 , (a, b) -> a * b)); System.out.println("最大值: " + list.stream().reduce((a, b) -> a > b ? a : b).get()); System.out.println("stream最大值: " + list.stream().reduce(0 , (a, b) -> a > b ? a : b, (a, b) -> null )); System.out.println("parallelStream最大值: " + list.parallelStream().reduce(0 , (a, b) -> a > b ? a : b, (a, b) -> null )); }
2.2.2.4 收集 collectstream流中collect是功能最多的操作,可以将流中的数据收集为一个值或者一个集合。主要是依赖于java.util.stream.Collectors类内置的静态方法。
collect(Collector<? super T, A, R> collector)中传入的是Collector对象, 主要使用为实现对象java.util.stream.Collectors。在Collectors中内置了很多具体收集的静态方法CollectorImpl<T, A, R>。这里简单理解下CollectorImpl<T, A, R>对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static class CollectorImpl <T , A , R > implements Collector <T , A , R > private final Supplier<A> supplier; private final BiConsumer<A, T> accumulator; private final BinaryOperator<A> combiner; private final Function<A, R> finisher; private final Set<Characteristics> characteristics; }
这里举两个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static <T> Collector<T, ?, List<T>> toList() { return new CollectorImpl<>( (Supplier<List<T>>) ArrayList::new , List::add, (left, right) -> { left.addAll(right); return left; }, CH_ID ); } public static Collector<CharSequence, ?, String> joining() { return new CollectorImpl<CharSequence, StringBuilder, String>( StringBuilder::new , StringBuilder::append, (r1, r2) -> { r1.append(r2); return r1; }, StringBuilder::toString, CH_NOID ); }
归集: 将流中的数据收集为集合(List、Set、Map)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static void collect () Student tom = Student.builder().age(19 ).name("tom" ).number(10 ).build(); Student marry = Student.builder().age(12 ).name("marry" ).number(15 ).build(); Student jack = Student.builder().age(12 ).name("jack" ).number(20 ).build(); List<Student> students = ListUtil.of(tom, marry, jack); System.out.println("======== collect ========" ); System.out.println(students.stream().map(Student::getAge).collect(Collectors.toList())); System.out.println(students.stream().map(Student::getAge).collect(Collectors.toSet())); System.out.println(students.stream().collect(Collectors.toMap(Student::getNumber, p -> p))); System.out.println(students.stream().collect(Collectors.toMap(Student::getNumber, Function.identity()))); System.out.println(students.stream().collect(Collectors.toMap(Student::getAge, Student::getName, (key1, key2) -> key2))); }
统计: 实际上就是聚合的那些操作(最大值、最小值、平均值、数量)
1 2 3 4 5 System.out.println(students.stream().collect(Collectors.counting())); System.out.println(students.stream().collect(Collectors.averagingInt(Student::getAge))); System.out.println(students.stream().map(Student::getAge).collect(Collectors.maxBy(Integer::compareTo))); System.out.println(students.stream().collect(Collectors.summarizingInt(Student::getAge)));
分组/分区: 分区是将流中的数据按照一定的规则分为两组数据(Map<Boolean, List>), 分组是将流中的数据按照一定的规则分成多组数据(Map<String/Integer/…, List<Object/String/Integer/…>>)。
1 2 3 4 5 6 7 8 9 System.out.println(students.stream().collect(Collectors.partitioningBy(item -> item.getAge() > 12 ))); System.out.println(students.stream().collect(Collectors.groupingBy(Student::getAge))); System.out.println(students.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.mapping(Student::getName, Collectors.toList())))); System.out.println(students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.averagingInt(Student::getAge))));
连接: 将流中的数据通过某个分隔符、前缀字符串、后缀字符串进行连接。
1 2 3 4 5 6 System.out.println(students.stream().map(Student::getName).collect(Collectors.joining())); System.out.println(students.stream().map(Student::getName).collect(Collectors.joining("|" ))); System.out.println(students.stream().map(Student::getName).collect(Collectors.joining("|" , "name: [" , "]" )));
2.2 中间操作 2.2.1 有状态 2.2.1.1 排序 自定义排序仅需要实现Comparator中的compareTo方法即可。实际上一些简单的排序在Comparator中都有静态实现,只需要通过lambda调用即可,比如降序排列Comparator::reversOrder()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private static void sorted (List<Integer> list) list.stream().sorted().forEach(item -> System.out.print(item)); System.out.println(); list.stream().sorted(Comparator.reverseOrder()).forEach(item -> System.out.print(item)); System.out.println(); list.stream().sorted(Integer::compareTo).forEach(item -> System.out.print(item)); System.out.println(); list.stream().sorted(new Comparator<Integer>() { @Override public int compare (Integer o1, Integer o2) return o2 - o1; } }).forEach(item -> System.out.print(item)); list.stream().sorted(Comparator.comparing(Student::getAge)).forEach(item -> System.out.print(item)); list.stream().sorted(Comparator.comparing(Student::getNumber).thenComparing(Student::getAge)).forEach(item -> System.out.print(item)); }
2.2.1.2 去重 distinct
通过流中元素的 hashCode() 和 equals() 去除重复元素。
1 2 3 private static void distinct (List<Integer> list) list.stream().distinct().forEach(item -> System.out.print(item)); }
2.2.1.3 切片 limit(n)截取前n个元素,skip(n)跳过n个元素。
1 2 3 4 5 private static void limitOrSkip (List<Integer> list) list.stream().limit(5 ).forEach(item -> System.out.print(item)); System.out.println(); list.stream().skip(5 ).forEach(item -> System.out.print(item)); }
2.2.2 无状态 2.2.2.1 映射 可以将一个流中的元素按照一定的规则映射到另一个流中。
map:接收一个处理函数,这个函数会作用到每个元素上,并为处理后的结果生成一个新的流。flatMap:接收一个处理函数,这函数会将作用到每个元素上,并为每个处理后的元素生成一个流 ,然后把所有流合并为流。(也就是说处理之后得到的数据是一个流,且这个流中的每个元素也是流。)
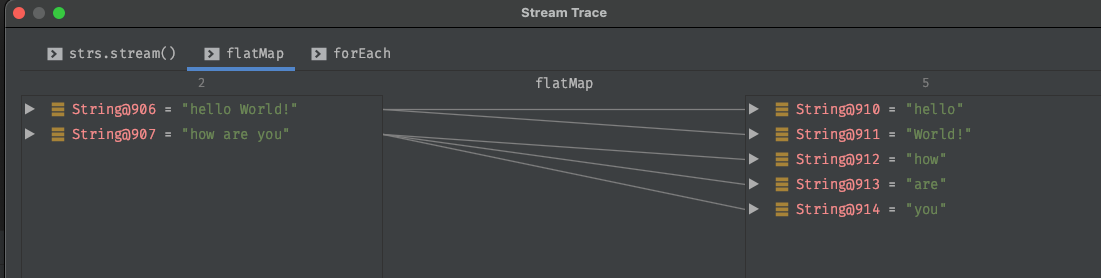
1 2 3 4 5 6 7 8 9 10 11 12 13 private static void map (List<Integer> list) list.stream().map(item -> item + 1 ).forEach(item -> System.out.print(item)); list.stream().map(Student::getAge).forEach(item -> System.out.print(item)); List<String> strs = ListUtil.of("hello World!" , "how are you" ); strs.stream().flatMap(item -> { return Arrays.stream(item.split(" " )); }).forEach(item -> System.out.println(item)); }
以下为debug模式下flatMap执行完成之后的结果。
2.2.2.2 过滤 filter
在实际的开发过程中比较常用的一个操作,接收一个函数,通过改函数判断是否需要过滤到元素。(一般情况下会配合映射map使用)
1 2 3 4 private static void filter (List<Integer> list) System.out.println("\n======== filter ========" ); list.stream().filter(item -> item % 2 == 0 ).forEach(item -> System.out.print(item)); }
2.2.2.3 消费 peek
主要是在debug中使用。
先来看一段代码:
1 2 3 private static void peek (List<Integer> list) list.stream().peek(System.out::print); }
执行后发现并没有任何输出。回到开头的介绍中,peek属于中间操作,在运行到终止操作时,此中间操作是不会执行。
1 2 3 4 5 list.filter(item -> item % 2 == 0 ) .peek(e -> System.out.println("被2整除的数: " + item)) .map(item -> item + 1 ) .peek(item -> System.out.println("结果: " + item)) .collect(Collectors.toList());
输出:
被2整除的数: 2
以上输出了流执行的中间过程,所以实际上流操作是在获取到一个元素后就会继续往下执行。
这里要注意:peek(func)接收的函数是一个Consumer,它是仅处理并不返回处理结果到流中。所以以下代码实际上执行也是没有效果的。
1 list.peek(item -> item + 1 ).collect(Collectors.toList());